Motivation
Recently Alex Kleiman, a coworker from the Replication team here at Delphix, was doing some performance testing that involved deleting more than 450 thousand snapshots in ZFS. That specific part of the test was taking hours to complete and after doing some initial investigation Alex notified the ZFS team that too much time was spent in the kernel.
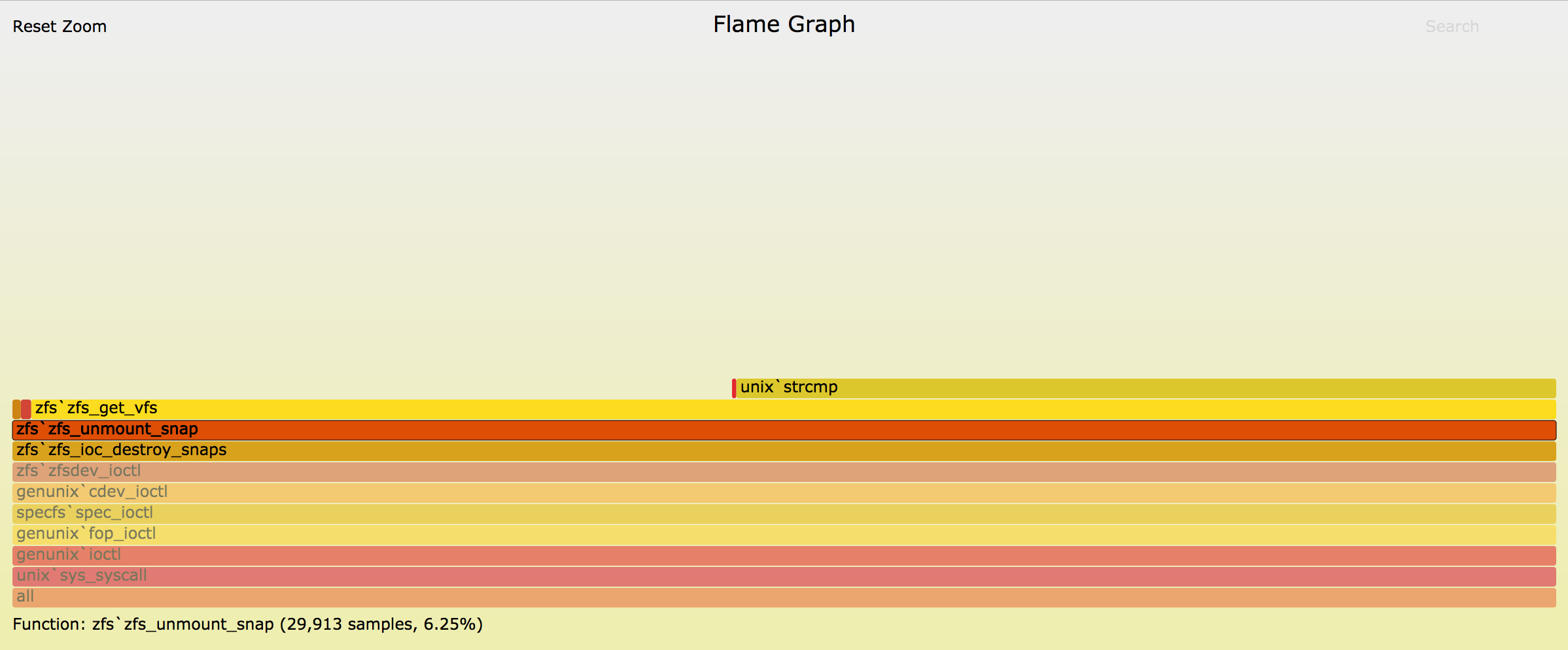
George Wilson jumped on the VM that the performance tests were running and was able to shed some light to the situation with the following flamegraph (interactive one can be found here):
{kind=link}
Analysis and Fix
From the above flamegraph we see that zfs_unmount_snap and its
subsequent function calls dominate the portion of the time we spend
in the zfs_ioc_destroy_snaps ioctl. There are many interesting
questions that we can ask about this, but the two main ones are the
following:
[1] Why are we spending so much time unmounting snapshots?
[2] Why do we spend so much time doing string comparisons while unmounting?
It goes without saying that we must unmount a snapshots before deleting
it, yet snapshots are rarely mounted (i.e. you have to specifically
perform operations in the ~/.zfs/snapshot/ directory). Thus we
shouldn’t be spending that much time trying to unmount them. Inspecting
the code, the following parts are of interest to the investigation:
/* ARGSUSED */
static int
zfs_ioc_destroy_snaps(const char *poolname, nvlist_t *innvl, nvlist_t *outnvl)
{
nvlist_t *snaps;
nvpair_t *pair;
boolean_t defer;
if (nvlist_lookup_nvlist(innvl, "snaps", &snaps) != 0)
return (SET_ERROR(EINVAL));
defer = nvlist_exists(innvl, "defer");
for (pair = nvlist_next_nvpair(snaps, NULL); pair != NULL;
pair = nvlist_next_nvpair(snaps, pair)) {
(void) zfs_unmount_snap(nvpair_name(pair));
}
...
The above snippet is our entrance to the ZFS ioctl in the kernel.
Name-Value pair lists (aka nvlists) are commonly-used in ZFS for passing
information around. Here the ioctl receives one from the userland (innvl)
that has an entry whose name is "snaps" and its value is another nvlist
which contains a list of all the snapshots to be destroyed. So before we
destroy any snapshots we go ahead an call zfs_unmount_snap on each of
them. In order to unmount a given snapshot zfs_unmount_snap has to first
find the VFS resource (i.e. mountpoint) of the corresponding snapshot, so
it calls zfs_get_vfs.
/*
* Search the vfs list for a specified resource. Returns a pointer to it
* or NULL if no suitable entry is found. The caller of this routine
* is responsible for releasing the returned vfs pointer.
*/
static vfs_t *
zfs_get_vfs(const char *resource)
{
struct vfs *vfsp;
struct vfs *vfs_found = NULL;
vfs_list_read_lock();
vfsp = rootvfs;
do {
if (strcmp(refstr_value(vfsp->vfs_resource), resource) == 0) {
VFS_HOLD(vfsp);
vfs_found = vfsp;
break;
}
vfsp = vfsp->vfs_next;
} while (vfsp != rootvfs);
vfs_list_unlock();
return (vfs_found);
}
The function does a linear search through all the VFS resources until it
finds the resource that we are looking for. Since snapshots are rarely
mounted and filesystems almost always are, the case is that for each snapshot
to be deleted we do one whole iteration through all the mounted filesystems
in the VFS layer. In terms of computational complexity that would be
expressed as O(mn) where m is the number of mounted filessytems and n
is the number of snapshots that we are trying to delete. That answers both
our questions.
To do a quick verification of the above hypothesis, I created 10 filesystems
in a VM and took a snapshot of one of them. Then I ran the following DTrace
one-liner that counts the number of calls to strcmp in tha code path while
destroying that snapshot:
serapheim@EndlessSummer:~$ sudo dtrace -c 'zfs destroy testpool/fs10@snap' \
-n 'strcmp:entry/callers["zfs_get_vfs"]/{@ = count();}'
dtrace: description 'strcmp:entry' matched 4 probes
dtrace: pid 4417 has exited
10
And after deleting one of the filesystems:
serapheim@EndlessSummer:~$ sudo dtrace -c 'zfs destroy testpool/fs10@snap' \
-n 'strcmp:entry/callers["zfs_get_vfs"]/{@ = count();}'
dtrace: description 'strcmp:entry' matched 4 probes
dtrace: pid 4417 has exited
9
So our hypothesis is correct, the runtime is indeed O(mn). Fortunately
for us, the structure representing any dataset has a pointer to its VFS
resource and looking up a dataset within ZFS is O(1), thus we should
be able to decrease the runtime from O(mn) to O(n).
Evaluation of Initial Fix
I created a new VM in which I created 10 thousand filesystems, each containing
one snapshot. As I named all the snapshots the same, I just ran zfs destroy -r <snap name>
to destroy all of them at once. The flamegraph that I got from this was very
similar to the one that George generated (original flamegraph can be found
here):
{kind=link}
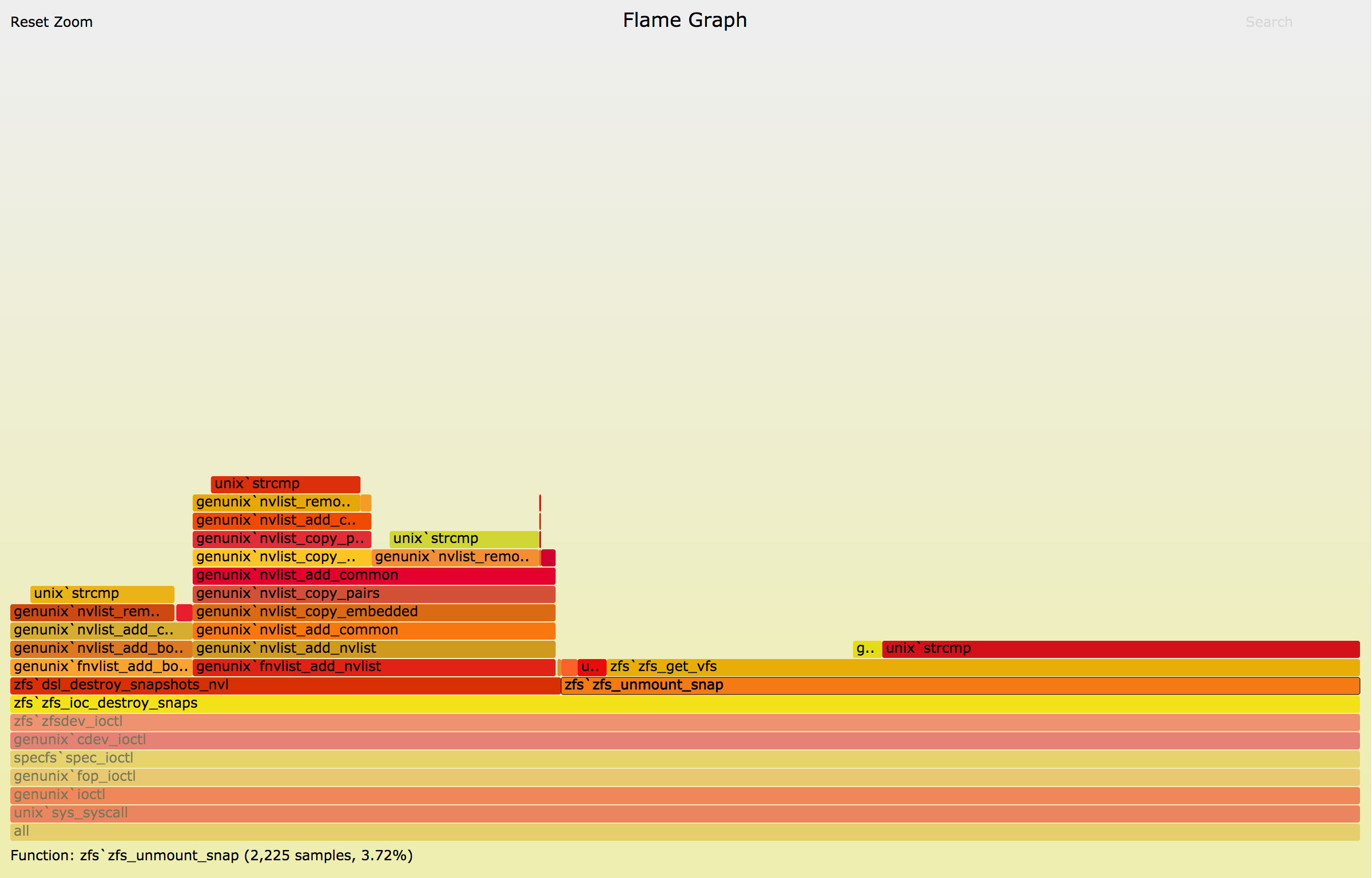
We can see that there are some other code paths down that ioctl but
zfs_unmount_snap still takes the majority of the time. After
applying the fix mentioned at the end of the previous section, the
results where the following (original flamegraph can be found
here):
{kind=link}
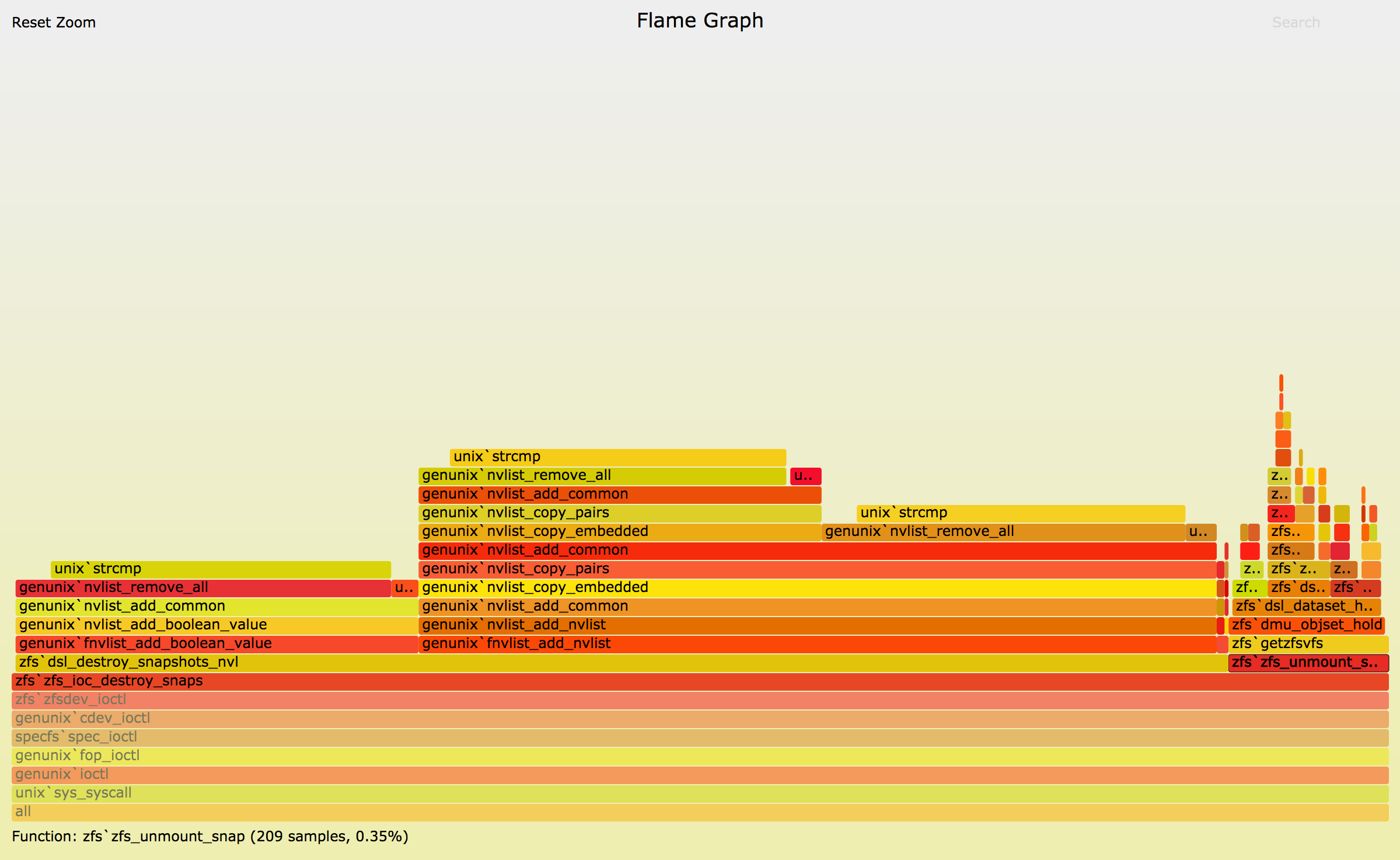
The difference in the number of samples in zfs_unmount_snap() is dramatic
(~2000 down to ~200 which is a 10x win). dsl_destroy_snapshots_nvl now
completely dwarves zfs_unmount_snap in terms of sample count (1500 vs 200).
After seeing the flamegraph, Matt Ahrens suggested that we investigate
the reason behind that stack taking time. He pointed that the issue should
be the uniqueness property being enforced in the nvlists used.
NV Pair Uniqueness
An nvlist can be created with the NV_UNIQUE_NAME flag which ensures that
no two entries have an identical name. The problem with this data structure
though, being a list, is that enforcing this property means that we have to
iterate through the whole list to make sure that the nvpair that we are about
to add doesn’t have the same name with any other entry, thus all the calls
to strcmp in the dsl_destroy_snapshots_nvl stack.
Once again, we are lucky as we don’t have to ensure this property in the
given use case. The reason has to do with how the nvlist is treated later
by spa_sync where we convert it to a LUA table that can more efficiently
enforce uniqueness because it’s implemented as a hash-table.
Evaluation of Updated Fix
After loosening up the uniqueness property of the nvlists used, I generated one final flamegraph (original flamegraph can be found here):
{kind=link}
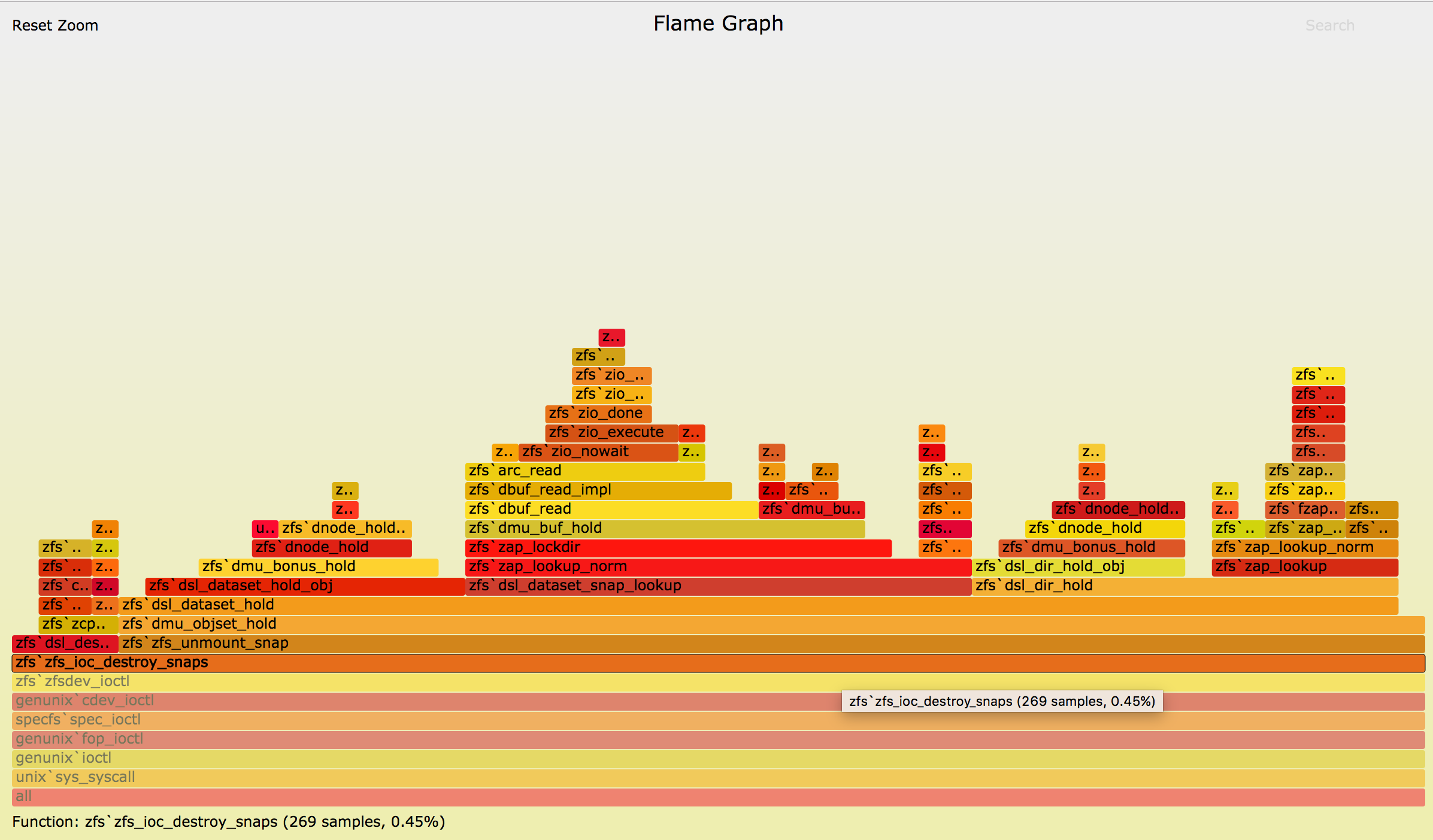
The sample count of zfs_ioc_destroy_snaps itself has decreased to the order
that of zfs_unmount_snap (3700 down to 200 samples).
Fin
Even though unmounting snapshots in ZFS is not an operation of high importance by itself, we saw how it can affect the performance of important operations like snapshot deletion. Another interesting experiment would be to measure how this change affects mass renaming of snapshots in a pool, as this operation attempts to unmount all snapshots before renaming them.
Future Work
For this performance fix, we were lucky that we could delegate the uniqueness property of NV pairs from the nvlist to the LUA table. Unfortunately, many other places within ZFS, and other parts of the illumos repo, that use nvlists don’t have the luxury to do something similar. Implementing a hash-table to be used internally within the nvlist interface, that can lookup a pair in constant time, would be an effective solution of dealing with this problem uniformly for all consumers.
Appendix A - Generating the Flamegraphs
For my experiments I ran the following DTrace one-liner while I issued the deletion of the snapshots:
sudo dtrace \
-xstackframes=100 \
-n 'profile-997{@[stack()]=count()}' \
-c 'sleep 30' | \
stackcollapse.pl | \
flamegraph.pl \
> svgs/$$.svg
The option -xstackframes=100 raises the limit for the number of stacks
returned by stack() from 20 (default) to 100, in order to avoid any
truncation. The probe profile-997 (sort for profile:::profile-997)
fires at 997 Hertz on all CPUs. The action stack() returns the kernel
stack trace, which is used as the key to our anonymous aggregation so
we can count its frequency. DTrace runs for 30 seconds while sleep 30
executes.
Resources:
Appendix B - OpenZFS patch
8604 Avoid unnecessary work search in VFS when unmounting snapshots